


Table Of Contents
This article builds on the platform described in the last seven parts, a Wordpress setup running on AWS using Docker. In this article, we will look into how to improve uptime and scalability for the service by replicating it across multiple servers. To allow for replication, several challenges need to be solved. How to handle this is covered in this article, including comments on a few problems I found like Docker nodes running out of memory and how to fix it. And network problems in Docker swarm mode.
To recap, the setup that we ended up with from the last seven parts, looks like this:
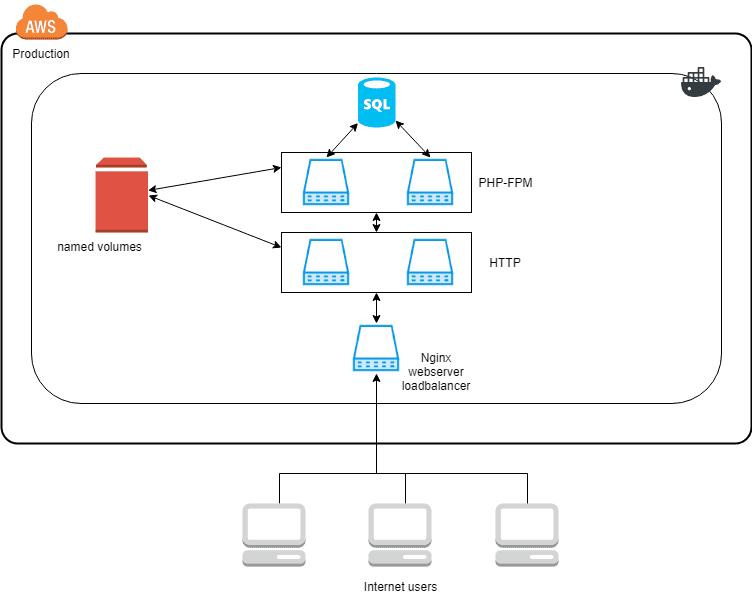
When a web request gets to the load balancer, it balances the request between the HTTP services. If the request is for a PHP script, it delegates the request to one of the multiple PHP backends. The PHP-FPM and HTTP services already support multiple instances of each container. But only on the same Docker host because of the dependency on the named volumes.
We would like to scale the setup to this architecture.
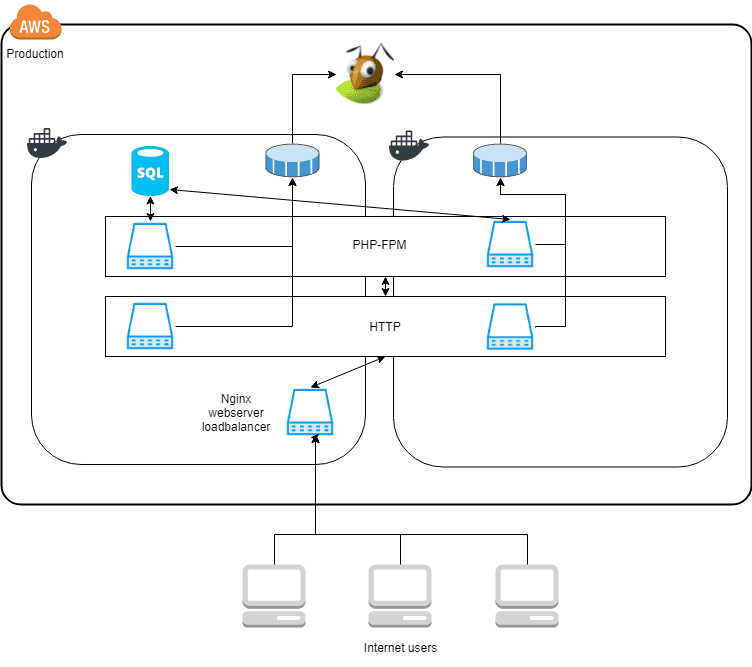
Now the “service boxes,” PHP-FPM and HTTP are scaled across two Docker hosts, shown by the box spanning the two Docker squares in the diagram. The requirements needed to do this, are covered below. Also, notice that the SQL server and the load balancer still only run on one of the Docker hosts. Replicating them will be a topic for another article.
To scale the setup across multiple servers, two problems need to be solved. Replicated filesystem, and orchestration of containers. Right now the Wordpress files for plugins and the media library sits in a Docker named volume. This volume sits on the Docker host where it is defined, so if the container starts on another server, then it will not have access to the same files, this is a problem that we must solve. The other problem we need to address is a way to handle distributing the containers across multiple servers, an orchestration tool. Both have various options to choose from which will be cover as we move on.
For info, the setup consists of two Amazon t2.micro EC2 nodes, 1GB of memory and a single 2.4Ghz CPU.
Filesystem replication
In the current setup, all the containers run on the same host; this makes it easy to use Docker’s named volumes to share files between the containers. When a user uploads an image inside the Wordpress administration, it is placed in the shared volume and is instantly available to the other containers. Since we are looking to move from a single Docker host to multiple hosts, named volumes are no longer able to fulfill the requirement. Docker provides no means to replicate files across various Docker hosts by itself. We need another solution.
Networked filesystems have been a requirement almost as long as we have had networks. So many different solutions exist. Just to name a few:
- NFS
- SMB
- GlusterFS
- AFS
- And many more
NFS and SMB are the filesystems I have prior experience with. But both of them use a client/server set up, which means a single point of failure, which we want to avoid. It also requires a dedicated host to act as the server which is not optimal. A truly distributed system would be better in my opinion. GlusterFS seems to be the most modern of the filesystems I looked at. It supports a cluster replication setup where files are replicated to the attached peers. So if a node crashes, the files will still be available on the other connected nodes. Since there is no client/server setup we do not need to dedicate a full EC2 instance to be the server, each node can be a part of the cluster setup with no need for additional instances.
GlusterFS does not come without its problems. As explained here GlusterFS can have trouble with many small files and many read/writes/updates to them.
GlusterFS was not a good solution in the case that the web servers were writing small files (meaning small number of kilobytes) often that change a lot e.g. session.xml being read, updated re-saved, read, updated, re-saved etc.
When many peers are attached, and a large file is uploaded to one of the hosts, it will give massive network traffic when this file is copied to all other peers. Luckily our use case is for GlusterFS to contain small to medium size media files for a Wordpress upload directory, and source files for the plugins enabled in the installation. Meaning that we have very infrequent updates of files, and often only creating new files. Which GlusterFS should handle fine. The situation where multiple peers are updating the same files should never happen.
Setting up GlusterFS
It is possible to have GlusterFS be used directly by a docker volume, using a plugin. But since it has status “proof of concept” I opted to set it up, straight, on the hosts instead. It gives the architecture shown below:
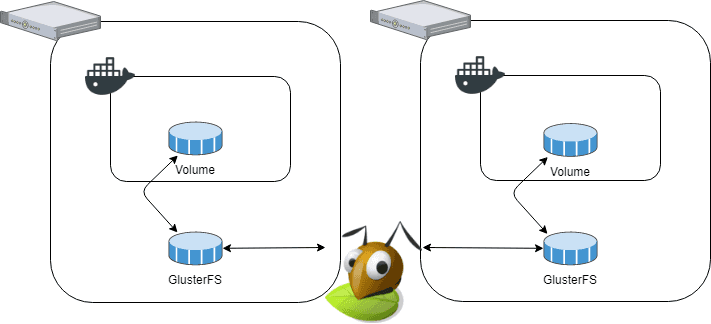
We have two hosts, both with Docker installed, each Docker has a volume mounted from the host. GlusterFS handles the replication between the hosts, transparent from the perspective of Docker. Setting up GlusterFS was easy, I used this guide which I will recommend if you want to try it out. GlusterFS has three concepts that we need to understand, bricks, replicated volumes, and mount points, as described in more detail here.
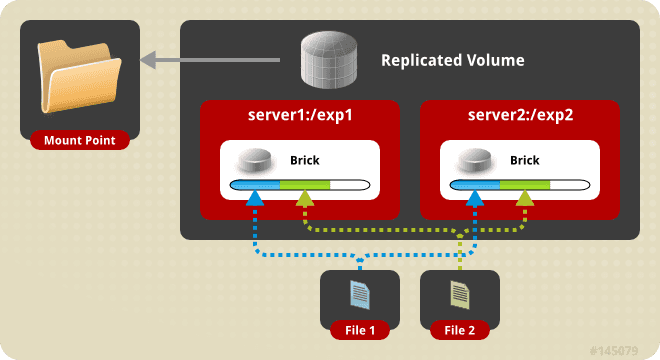
A brick is essentially a block space device, i.e., a hard disk. As shown in the diagram above(borrowed from GlusterFS’ website), each server has its own brick. The bricks are combined into a replicated volume which is mounted on each host. Then the GlusterFS daemon handles replicating the files. It is surprisingly easy to set up, and I had no problem with it yet.
GlusterFS with Docker
I iterated through a few different ideas before a found a solution that I was happy with.
Replicating Docker named volumes
In the original set up, Docker used named volumes; this is volumes managed by Docker automatically, the data lives in the directory /var/lib/docker/volumes, each named volume has its own folder. My first thought was to change this parent folder to be managed by GlusterFS. But this gave two problems.
- Docker maintains a database file metadata.db inside the directory, this file is used by each Docker node, to handle the volumes on that node. So this file cannot be replicated. When I tried to replicate it anyway, Docker on the worker machine failed to start up. So this did not work. I do not think it is even possible to do it.
- If we want to have volumes that are local to a machine, there is no way to separate them from the replicated volumes in this setup, which is another drawback - for example, the volume for MariaDB we do not want to replicate.
So I gave up on this idea fast :-)
Using a GlusterFS volume for each Docker volume
Secondly, I thought to create a GlusterFS volume for each Docker volume to have a one-to-one layout. But in GlusterFS there is a one-to-one mapping between a brick and a volume, it is not possible to create multiple volumes on a single brick. It seems there are talks in the community about ways to get around this limitation as described here. But it has not made it into any releases, yet. The architecture gives the problem that to support multiple GlusterFS volumes a disk device is needed for each volume, making it very cumbersome to set up new volumes. So I also gave up on this idea.
Using Docker bind mounts to a single GlusterFS volume
This is the setup I ended up using.
I created a single GlusterFS volume, mounted it to /data/storage/, in this directory I created a folder for each of the named volumes I needed in Docker. Then I copied the files and switched the docker-compose.yml file to use bind mounts instead of named volumes. It was almost an instant success. Initially, I moved all the named volumes to this setup, including the data directory for the MariaDB server. It was a bad idea since it is to IO heavy for a replicated filesystem, so I moved this single volume back to a normal named volume, which is the only named volume left in the service stack, the rest of the volumes run on GlusterFS.
Experience running GlusterFS
After running with the setup for a bit, I noticed that when I put load on the websites, GlusterFS uses quite a bit of CPU, on both nodes.

Since all files are copied to every node with a replicated volume, I thought that GlusterFS would handle read load smoothly, close to local disk storage. But it seems that this is not exactly the case.
Initially, I noticed that I entered the wrong node name in my _/etc/_fstab settings. On the master node, the worker1 volume was mounted, and reverse on the worker1 node. Because of this, I suspected that the reads might happen across the network instead of using the local brick. When I changed it, the CPU usage dropped, but not by a significant amount, and the speed was unchanged.
After a lot of digging, I found two articles that explain part of the problem. GlusterFS uses hashing to select the node to process the request. It can be disabled and then GlusterFS will default to use the local replica. It gave a speedup and lowered the remote nodes CPU load.
The other problem is the metadata requestion process in GlusterFS as described here.
The downside to this method is that in order to assure consistency and that the client is not getting stale data, is needs to request metadata from each replica. This is done during the lookup() portion of establishing a file descriptor (FD). This can be a lot of overhead if you’re opening thousands of small files, or even if you’re trying to open thousands of files that don’t exist. This is what makes most php applications slow on GlusterFS.
Which is exactly the case with this setup, thanks, Joe!
To mitigate this PHP must not call stat() on files, this can be controlled by the opcode cache in PHP. In the most aggressive setting PHP caches all files on access an never use the local files again. But this can be controlled in many ways, as described here.
I have not done extensive load testing on the setup yet, so I am not aware of how it will scale.
Replicating Docker
To handle replicating the Docker containers across nodes an orchestration tool is needed. Like with the filesystems above multiple solutions exist.
- Docker Swarm
- Kubernetes
- Amazon ECS
- And many more
Docker Swarm is the orchestration tool that ships with Docker, so I hope this will make the setup smoother, so that is the tool I will use. In the end, Docker swarm proved to be quite a headache to set up, but I got it working in the end.
With the files replicated the last part missing is the network. Since I run this setup on AWS I need to start up the two EC2 instances in the same security group; then they will be part of the same subnet allowing them to communicate. When Docker runs in swarm mode, it creates an overlay network that makes each node able to communicate. But remember to add rules in the security group to allow them to communicate, initially, I forgot to allow UDP traffic between the nodes in the security group, and then the network does not work. It took me a couple of hours to figure out why nothing worked!
Setting up Docker swarm is straightforward. Run the following commands:
- “docker swarm init” this starts Docker in swarm mode on the master node; this was already handled earlier
- “docker swarm join-token worker” this command outputs the command to run on the worker node to join the swarm
- run the join command on the worker node; this should output ”This node joined a swarm as a worker.”
Now the swarm is ready to distribute containers across the hosts. But a few of the containers are required to run on the master node, for example, the database because it is here the named volume for its datafiles resides.
It is handled in the deploy directive for each service like this:
db:image: mariadbvolumes:- db-data:/var/lib/mysqlenvironment:- MYSQL_ROOT_PASSWORD=xxxdeploy:placement:constraints:- node.role == manager
Now the swarm will only run this container on the manager. You can view the complete docker-compose.yml file here.
Replicated nodes
The php-fpm and http service, we want to have them running one instance on each of the nodes. It is handled automatically. Initially, the setup had the directive, replicas: 2 which automatically tries to spread the containers across the swarm. If a node crashes we end up with two running instances on the other node.
Networking
Docker swarm networking, a HUGE hassle, I’m not even 100% sure that it is working stable yet. But in the process of debugging it, I did learn a lot about Docker networking.
Docker swarm uses what they call an ingress routing mesh network that spans all the nodes in the swarm. This network makes it possible for connections outside the swarm to access the services. It does this in a fully transparent way, meaning that if for example, we run a web server on port 80. Then one of the nodes will have the actual public IP address bound to a network interface. But the service does not need to be running on the same node, the routing mesh will forward the connection to the correct node.
So it will not be a requirement to run the load-balancer service on the manager node, if it runs on the worker node the connections will be forwarded, transparently.
I did end up not using this feature because it caused connections to be dropped. Which is quite sad, because this feature is awesome. There are many open issues on GitHub on this feature.
The problem I observed was that when running a simple test using ab.
ab -c 5 -n 10 http://example.com/
Meaning, use five concurrent connections to the server and make a total of 10 requests. Then the first five requests will be fine, and the 6’th request will have “no route to host”. If I increased the concurrent connections to 100, the first 100 connections were fine, and the rest failed. I have no idea why this happens, and my efforts to debug it all failed. Eventually, I stumbled on this issue which gave a workaround.
The routing mesh allows us to have the load-balancer run on any node. But with this workaround port 80, is not bound to the routing mesh, but to the actual port 80 on the node itself, bypassing the routing mesh. It forces the load-balancer service to run on the manager node always to accept connections from outside.
loadbalancer:image: 637345297332.dkr.ecr.eu-west-1.amazonaws.com/patch-loadbalancer:latestbuild: loadbalancerports:- target: 8080published: 80protocol: tcpmode: host
It is the ”mode: host” that causes this change. If anyone knows more about the routing mesh and have an idea to why this problem happens in the first place, please let me know.
Network timeout errors
I also struggled with another problem for a long time. When processing requests the load-balancer would get “Host is unreachable” when trying to pass on the request to an upstream server.
[21/Apr/2018:09:57:13 +0000] 10.255.0.5 - - - datadriven-investment.com to: 10.0.0.15:80: GET /wp-content/robots.txt HTTP/1.0 upstream_response_time 0.115 msec 1524304633.168 request_time 0.1152018/04/21 09:57:14 [error] 5#5: *781 connect() failed (113: Host is unreachable) while connecting to upstream, client: 10.255.0.5, server: datadriven-investment.com, request: "GET /wp-content/robots.txt HTTP/1.0", upstream: "http://10.0.0.15:80/wp-content/robots.txt", host: "datadriven-investment.com"
Eventually, I traced the problem to the DNS service inside docker. The service names from the compose file are resolvable by the internal DNS-service. It is a two-step process. Each service container is assigned an IP address, and each service is assigned a virtual IP. The purpose of the virtual IP is to support a round robin type of load balancing. Each time a request is made to the service’s IP the request is connected to a different service container. It means that when looking up the service name like below, we get the virtual IP back.
# nslookup httpName: httpAddress 1: 10.0.0.21 ip-10-0-0-21.eu-west-1.compute.internal
In this case, it resolves to the virtual IP. If instead, we use the hostname tasks.http then the DNS will show the actual IPs of the services.
# nslookup tasks.httpName: tasks.httpAddress 1: 10.0.0.22 patch_http.2.nppi5a3zppqagt301wx3sgofi.patch_defaultAddress 2: 10.0.0.18 patch_http.1.zkeon58iai0p0bg8by3pb5wzp.patch_default
The virtual IP should be stable then containers are scaled up/down, even though the actual IPs of the containers might change.
The “no route to host” error from above occurred because the DNS still contained IP addresses of containers that were not running. Meaning of course that the IPs did not work. I never found out why this was the case. I found a few others that reported the same problem but with no solution. It disappeared after a few reboots of the entire server, but why, I never found out.
It seems that stopping Docker, deleting the file /var/lib/docker/network/files/local-kv.db clears the DNS and it gets it correct when Docker starts again.
Resource constraints
Low memory in the servers proved to be quite a problem. With only 2x1GB the room for services that consumes a lot of memory is not very large. For example, the MariaDB service can easily consume 400-500MB alone.
One of the reasons this happens is that the standard config is that Docker tells each service how much memory is available, and that limit is equal to the memory available on the node. Which means that if five services run on the node, each is told that they have 1GB memory available, so if they start caching stuff and consume the memory they will together want to use 5GB. Which causes the node to crash/swap.
This resource limit caused the nodes to crash a lot, which is evident on the uptime tracker:

Not a very good track record. But it should improve as the setup gets more stable.
The way to avoid this is to tell each service how much memory it is allowed to consume. It is done through the compose file.
db:image: mariadbvolumes:- db-data:/var/lib/mysqlenvironment:- MYSQL_ROOT_PASSWORD=xxxdeploy:placement:constraints:- node.role == managerresources:limits:memory: 300M
Using this configuration, the db service knows that it only has 300MB available. It causes two things to happen, first MariaDB knows the limit and will work to try not to overshoot it by flushing caches and so on. If the container hits the limit, it will be restarted by Docker. So it is important to leave the limit high enough that it is not at risk to get hit under normal load.
Right now the db service uses around 170MB under normal load. So there is space available.
Things to notice
When upgrading Wordpress, it is the fileserver services’ responsibility to copy the updated files to the mounted volume. It does not matter which node this service is started on since the copied files are replicated to the other nodes by GlusterFS.
This has by far been the most time-consuming and frustrating part of my ongoing work with Docker. I never anticipated this amount of problems with the network, but I hope it will get more stable in future releases of Docker.
Share

Related Posts
Legal Stuff