


Table Of Contents
Real men do not take backups, but they cry a lot
But I rather not cry too much :-) I try to have a good backup solution. After all, I do spend an awful lot of time creating data; it would hurt a lot if it were lost by accident. Especially since a backup is easy to set up and cheap.
Amazon S3 is my go-to solution for cloud data storage. It is designed never to lose data and to be resilient to disasters. On top of that, it is cheap.
In this article, I dive into what you need to know about Amazon S3 before you start using it for your backup solution.
S3 allows you to store an infinite amount of data. With files size up to 5TB per file. Essentially it should be enough for anyone, and even Netflix uses S3 for their storage needs. It is a well-designed storage solution that is scalable for many use cases.
You can interface with S3 in many ways; they are described here. Most essential for me is the Linux console utility s3cmd it allows me to upload any file or directory from a Linux machine to S3. That is what I use for backup.
S3 is designed with a REST API for interfacing so you can even build your own tools to interface with it.
In S3 you work with a “bucket” which is a name you create to reference the place where the data is stored. A bucket can be created using your Amazon Console.
The create wizard looks like below. You need to write a globally unique name as the bucket name. The rest of the settings you can leave to the default settings.
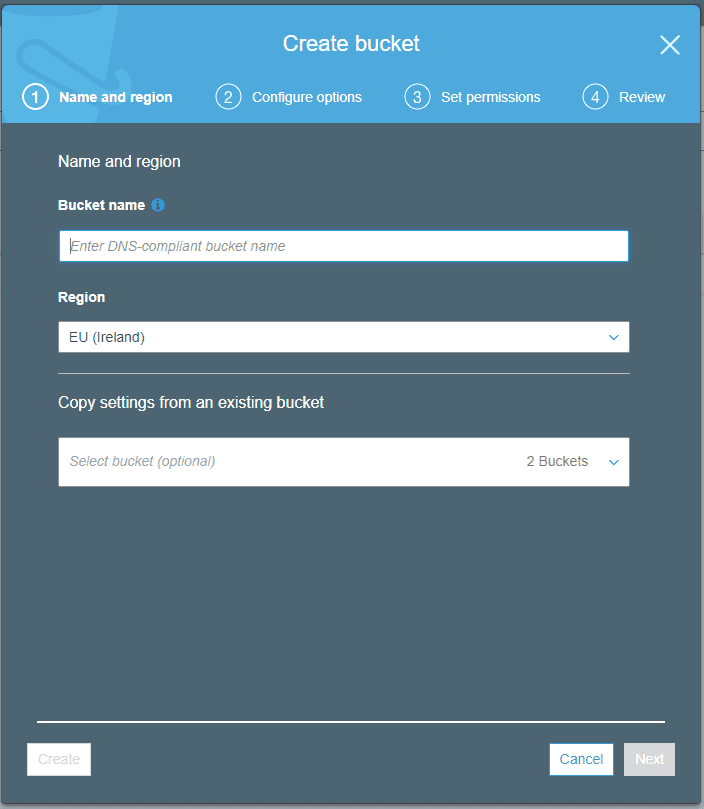
Each bucket is placed in the region you select. In the screenshot EU(Ireland) is selected. Acces is handled by the AIM system in Amazon, so you need to create a user to upload/download files. More on this later.
Set up backup
I need to backup the upload directory from my websites and a dump of the database. It is handled by two Docker containers. One to do file backup and another for database backup that I build. Both use the s3cmd tool to copy the files.
To have the s3cmd tool copy files, you need your access-key and secret-key. You can find them using the guide here.
Now you can copy data in your S3 bucket with the s3cmd tool!
S3 Storage classes
Each file in S3 is placed in a specific storage class. You can see the storage class next to each file.
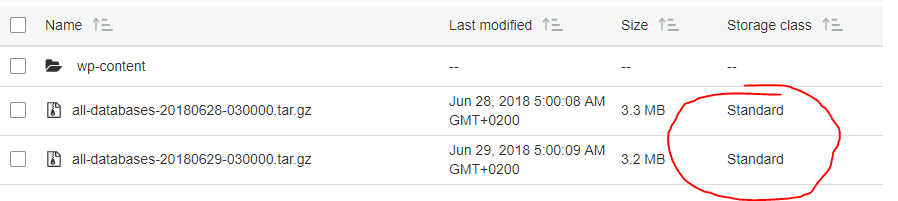
In the standard storage classes, each file is replicated to three different Availability Zones inside the selected region. It also supports low latency access.
There are other storage classes as explained here. We hopefully do not need low latency read access to our backup, so we might want to save some money selecting Standard-Infrequent-Access storage class instead. The storage price is lower, at around 50% cheaper than Standard. But data upload and download are more expensive. So you would need to calculate if it makes sense to change it. I think it would mostly make sense to do if you store backups for a long time.
S3 supports lifecycle policies for stored files. That allows you to modify the files stored in S3 with a set of rules. It will enable, for example, to transition files from one storage class to another.
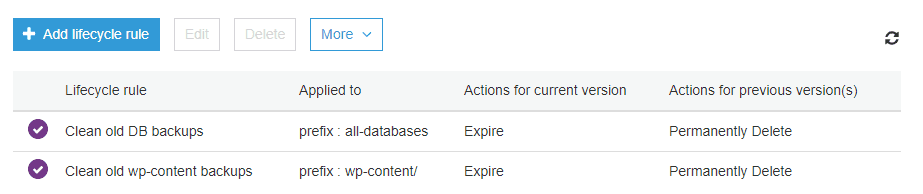
You can also add rules to delete files automatically and much more. This makes it easy to set up something similar to
- Backup the web files every day - this could be handled by s3cmd and cron
- Delete all backups older than 30 days
- Keep one backup every week for one year
- Automatically change the storage class on the weekly backup to Glacier
I retain the last 30 days and delete everything older than that. So my setup is quite simple.
More security with geo-replication
Amazon has designed their services to be resilient to disruptions. Each region is able to run even if other regions are not available. Amazons track record is quite good with regard to downtime. So I do expect the normal inter-region replication to be very sage. But we can easily set up S3 to replicate all our files to a bucket in another region. This provides maximum safety for our files.
Setting up replication is easy. You need to create a new S3 bucket in another region. Just a normal bucket.
Then you can set up replication on the original bucket and select the newly created bucket as the destination.
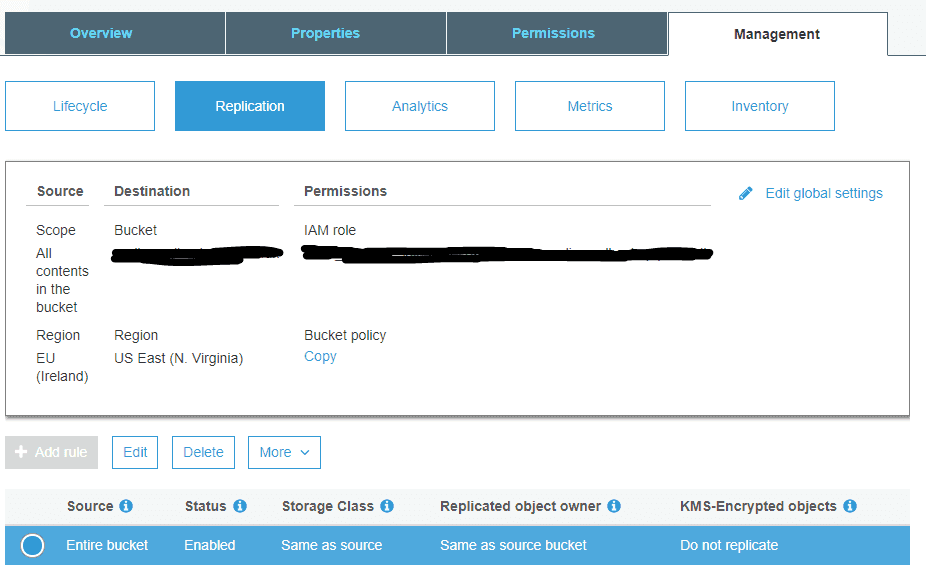
Notice that existing objects are not replicated automatically, only newly created objects. So if you need your old backups replicated you need to copy them manually.
All user actions are replicated, like new file and deletes. But lifecycle policy actions are not replicated. So if you use lifecycle policies to change storage classes or delete expired files, you need to create the policies in the remote bucket, they are not created automatically.
That is all there is to it; now you have a geo-replicated S3 bucket.
Final thoughts on S3
I find it very cool to have a cloud storage with infinite storage capacity. When it is so easy to interface to, then it is useful not only for backup but for many other purposes.
I hope to investigate more use cases for S3 in the future.
Tags
Share

Related Posts
Legal Stuff