


Table Of Contents
Clean: Simple But Not Easy
As technology gets smarter, our dependence on software for the simplest tasks becomes more and more embedded in our daily lifestyle.
We rely on our phone alarm to wake us up in the morning. Alexa turns our lights on and off, tells us the weather forecast for the day, plays our favourite tunes, orders us lunch—and so on and so forth. We’re even starting to get used to the idea of driverless cars.

The lightning speed at which technology keeps evolving places immense pressure on developers (you and I) to write the programs that tell these devices and machines what to do.
Unlike products operated by hand—like a grandfather clock that needs to be wound weekly to power the mechanism—computerised gadgets, appliances, and machines need frequent software updates to constantly improve their features and fix bugs in the software.
It’s this perpetual need to upgrade the program that calls for code that’s easy to read and understand so it’s easier to change.
“Indeed, the ratio of time spent reading versus writing is well over 10 to 1. We are constantly reading old code as part of the effort to write new code. …[Therefore,] making it easy to read makes it easier to write.“
Robert C Martin
The more self-explanatory the code is, the less effort it takes to understand and write new code. A solid foundation of high-quality code makes it infinitely easier to grow, maintain, and improve over time. Without it, the best architecture and inspired ideas can’t be executed effectively.
Clean Code is a programming philosophy that focuses on the finer details like how the code reads, where the whitespace is placed, what we call things, and so on.
As the saying goes, “If I had more time, I would have written a shorter letter.” The same principle applies to programming. Clean code is simple but not easy. Simplifying something always takes more effort because it requires significantly more thought and consideration.
Keeping the code simple doesn’t mean taking the easy way out. It doesn’t mean cutting corners and compromising on features. Code is simple when the concepts and features are expressed as directly and clearly as possible.
While clean code is the ultimate goal, it isn’t always realistic. As software developers, we get paid to deliver features. It can be a difficult balance to strike: spending time on clean code vs shipping quick and dirty.
It might seem faster to write an isolated piece of code in whatever way that allows it to work, but that piece of code will most likely need to be modified later to add new features to it. It’s the process of changing it that incurs a high cost if the old code is badly written.
Quality code costs more initially as it’s more time-consuming to write, but readability of the code helps us speed up over time as we grow the software. The point of intersection between the blue and yellow line is where quality code overtakes bad code exponentially in the long-run.
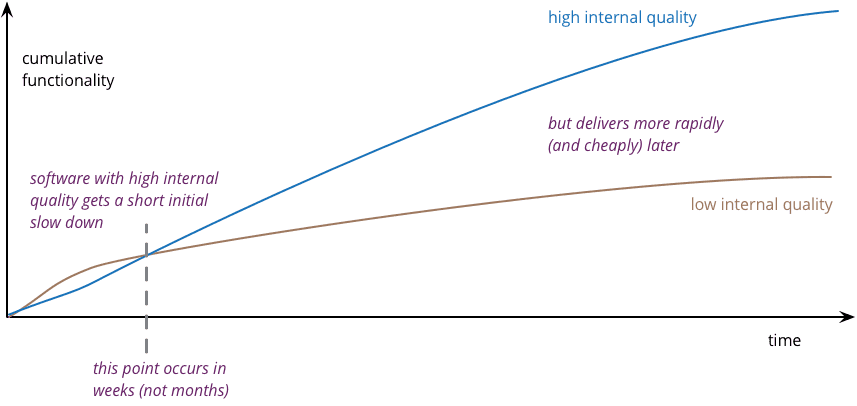
Perfectly clean code does not exist, just as a piece of writing can’t ever be perfect. The point is not to get stuck trying to perfect the code; we would never ship in this case. Instead, we need to make sure it’s as clean as possible while working within the time-frame we have.
It’s important to remember that software development is done to create business value. We will often be under pressure to deliver features as quickly as possible, which might not allow us to achieve the high code quality we would like. If we have to, we must compromise, but it’s our responsibility to advocate the benefits of high-quality code as much as we can.
What is Clean Code?
As a concept, Clean Code is code that’s easy to understand and easy to change. While it sounds simple and agreeable, this broad definition doesn’t provide specific guidelines on how to achieve it or objectively measure how clean the code is.
Due to the wide range of perspectives offered by most books on software quality, there is currently no definitive standard for what constitutes code that’s “easy to understand” and “easy to change”.

What’s important to note is that clean code isn’t just about the code. We need to look at the big picture — the internal code quality will have a ripple effect on all stages of software development and its external quality — from new programmers who have to work with it, to the way it shapes the architecture, from interactions with the business teams, to end-users’ experience with it.
The benefits of clean code include the following:
Easier to Test
It’s always much harder to do automated testing on messy, complex code. More importantly, clean code is easier to diagnose when something breaks. Just like dirt is more noticeable on a clean surface, so are problems easier to spot in cleaner code.
Cheaper to Maintain
Due to the frequent changes and addition of new features in modern software, the bulk of the cost lies not in development but in maintenance.
Every minute spent trying to understand the code is a minute lost on designing or implementing the solution. Being able to lower the maintenance cost will have a compounding effect on our ability to ship quality features faster.
Bugs Will Stand Out
Clean code, being simpler in composition, forces bugs to stand out as it’s easier to spot errors in the code when they are not obscured by unnecessary complexity.
Greater Programming Joy
Bad code is painful to maintain, period. We would all experience greater joy in our work if we only dealt with high-quality code.
Why Should You Care About Clean Code?
Compilers will execute the code regardless of its quality, so why does it matter if the code is clean? True, you can get away with messy code for a while, but its long-term repercussions will make you wish you had invested time in getting it clean from the start.
The smallest details can make the biggest difference. If we write code with the reader in mind, it would be a joy to read — something we would collectively benefit from in the long run.
“Any fool can write code that a computer can understand. Good programmers write code that humans can understand.”
Martin Fowler

To Feel the Programming Joy
Developers aspire to work in a challenging but productive working environment where we are able to contribute, learn, and grow, rather than being caught in an endless cycle of fixing trivial errors over and over again.

Having confidence in the codebase allows us to push our creative boundaries further and add real value to the code. It allows us to feel the programming joy.
Contrast this with the common scenario where a customer requests for a new feature which, by your estimation, shouldn’t take more than a couple of days.
You start tinkering with the code and almost immediately, problems start popping up. Now you need to connect four different modules and then make changes in 20 different places, all the while keeping your fingers crossed that nothing else breaks. It takes 6 days for you to eventually deliver the feature.
Not only is this stressful for you, but it also causes the customer to lose confidence in your skills as a developer. It’s a lose-lose situation.
To Avoid Killing People & Costing Businesses Huge Losses
Software failures can cost lives and lead to billion-dollar payouts, as we’ve seen in Toyota’s case of unintended acceleration which killed one of the car’s occupants. The cause: defective, bug-ridden source code.
While most software bugs might seem harmless, compromising on quality standards creates a culture of complacency which can lead to catastrophic disasters.

Take the Ariane 5 rocket launch in 1996. A mere 37 seconds after lift-off, the rocket flipped 90 degrees in the wrong direction, went into self-destruct mode, and was ultimately consumed by a gigantic fireball of liquid hydrogen. The disastrous launch cost approximately $370m, widely acknowledged as one of the most expensive software failures in history.
In 2012, Knight Capital Group deployed a new software update to their production servers which, unbeknownst to them, had a faulty algorithm. 45 minutes into the start of the trading day, the company had lost a staggering $460 million and was subsequently fined $12 million by the Securities Exchange Commission for various violations of financial risk management regulations.
There were multiple factors that led to the disastrous software update, but the lack of a formal code review or QA process to check that the software had deployed correctly played a major role.
Maintaining high quality standards is important to ensure that we’re not caught off guard by oversights that could easily be rectified by validation tests and quality reviews.
For Sustainable & Scalable Productivity
The Navy SEALs train with the philosophy that
“slow is smooth and smooth is fast”.
In high-speed combat situations, moving smoothly and dynamically assessing risk comes first — the objective is not to run to one’s death.
We could apply the same philosophy to programming. Greenfield projects typically start out fast as developers get to create the source code from scratch. But in the haste to ship quick and dirty, we dig ourselves into a hole with the pile of mess that keeps getting bigger and deeper by the day.
Productivity goes down the drain as we spend precious hours trying to unravel the tangles, twists, and knots in the code. Management adds more developers to the team, thinking more brains will lighten the load, but all that does is add to the mess. And so the cycle continues and the technical debt grows with each passing day.
It’s natural to make a mess in the beginning when we’re figuring out the solution to a problem; that’s how the human brain operates. But we need to distil the valid ideas and concepts from the mess so that what’s left is pure, simple, and clear.

Instead of checking-in code as soon as it’s functional, we need to refine it so it’s easily understood and changed by all developers. We need to make sure that the code is high quality for sustainable and scalable productivity.

Get actionable insights on how to improve your code directly in your Inbox. Sign up now!
How To Write Clean Code
The human mind is not able to solve a problem and think about expressing it clearly at the same time. That’s why we start by creating code that works and then refactor the code to be clean.
It’s tempting to want to move on once you’ve got the code to do what it’s supposed to do, but refactoring the code into a high-quality state is critical to ensure smooth productivity when working on it in the future.
There are many different aspects of writing clean code. It will take time and diligent effort to master these aspects, but with time and practice, you’ll be proficient enough to make good choices and tradeoffs.
Clean code is not just one thing. It is the result of various aspects working together to make a codebase simple and easy to work with. The following are some of the key aspects you will need to master to be able to write clean code.
Test-Driven Development (TDD)
There is a natural tendency to resist changing the code after you’ve spent hours to get it working. Doing double work is painful, but there is a better way. Instead of pushing refactoring to the end, there is a process that builds it into the coding process. It’s called Test-Driven Development (TDD).
It’s not a requirement for writing clean code, but it greatly enhances the process, in my opinion. TDD entails writing the tests before the production code in its test-first approach, which makes the test code just as important as the production code. It is the tests that enable us to create maintainable and flexible code.
Chapter 9 of the Clean Code book (page 132) details the FIRST principles of unit tests:
- F**ast**: Run many hundreds or thousands of tests per second
- I**solated**: Failure reasons become obvious
- R**epeatable**: Run repeatedly in any order, at any time
- S**elf-validating**: No manual evaluation required
- T**imely**: Written before the code

Clean Code: A Handbook of Agile Software Craftsmanship
For a more in-depth review, here’s a deeper dive into TDD.
Abstraction Level
One of the factors that cause messy code is the mixture of abstraction levels. When we’re writing code, it’s natural to end up with a mishmash as we implement different ideas and concepts as they occur to us. Once the code is working, however, we need to refactor the code to the same abstraction level.
Robert C Martin cites the example of the way a news article is written to demonstrate the significance of this.
We start by reading the news headline, which gives us the gist of the article. If it sounds interesting, we’ll read the first paragraph, which is often an abstract or overview of the piece of news. If we’re still interested, we’ll keep reading until the point we get bored and tune out.
The reason we’re able to do this is because the structure of the article uses a top-down narrative, starting from a high-level overview and going into more detail with each subsequent paragraph. It allows the reader to escape at the earliest point.
Compare this with an article without a clear structure that starts with a detailed paragraph and then switches into a high-level overview and then back into the details — you would have no option for an early escape.
You would need to read the entire article (most likely a few times) before you’re able to make head or tail of it, and it will be a painful reading experience. That’s what it’s like to read code with a mixture of abstraction levels.
Robert C Martin refers to this as the Step-Down Rule in his Clean Code book:
“We want the code to read like a top-down narrative. We want every function to be followed by those at the next level of abstraction so that we can read the program, descending one level of abstraction at a time as we read down the list of functions. I call this the step-down rule.”
Naming
To quote Phil Karlton, the two hardest things in programming are cache invalidation and naming things.
The “things” in programming refer to variables, classes, services, and functions. When we name these things, we give them meaning, context, and life. If we use confusing, wrong, or misleading names, the piece of code won’t make sense to the reader.
There are a number of guidelines for picking good names:
- Use intention-revealing names
If a name requires a comment, it’s not revealing its intention. The key is to use names that are descriptive.
- Avoid confusion and disinformation
Don’t use names that have multiple meanings or are associated with well-known brands or platforms. Don’t use cultural references, puns or cute names.
- Make clear distinctions
Noise words like ProductInfo, ProductData, data and info all mean the same thing, which doesn’t communicate the difference between each.
- Use names that are easy to pronounce
If the names aren’t pronounceable, you’ll have problems discussing it. Or you might have different people pronouncing it differently, causing confusion and miscommunication.
- Class names should be nouns
Since class names are used to categorize methods and variables, it makes sense to use nouns and noun phrases that act as identifiers such as Customer, WikiPage, Account.
- Function names should be verbs
In contrast, function names are used to describe actions, therefore they should be verbs or verb phrases such as postPayment, deletePage, save.
- One word per concept
Consistency is key for clarity. You should only use one word per concept. Fetch, retrieve, and get all refer to the same thing, just like controller, manager, and driver. Using different but similar names for the same concept only creates confusion.
- Solution domain names vs problem domain names
Solution domain names (computer science names) such as names of algorithms or design patterns should be used wherever possible, and problem domain names (business names) used as an alternative.
- Avoid typos
And of course, it helps to make sure the names are spelled correctly!
Functions
Here are some of the most important rules for functions:
- Keep them small
Functions should be as small as possible, ideally only a few lines long and definitely not more than 20 lines. The smaller it is, the more precise its name can be.
- It should do one thing and do it well
A function should only do one thing, which keeps it small and easy to name. You’ll know that it only does one thing if the steps in the function are only one abstraction level below the name of the function.
This is important as functions are used to deconstruct a larger concept into smaller steps one abstraction level at a time.
- They shouldn’t have side effects
Keep your functions pure. Side effects are unintended consequences of your code, which can create nasty bugs. And they are difficult to reason about.
- Use verbs as names
Since functions refer to actions, function names should always be verbs and they should be descriptive with the right keywords.
- Error handling
Exceptions are better than error codes.
- Don’t Repeat Yourself (DRY)
Duplicate code requires changes in multiple places where there are changes in the logic. For this reason, the same code should never be repeated.
There’s no danger of having too many functions as each function will have a name and they will end up in the right places. Classes contain functions so they will end up in the right place after refactoring.
Function Arguments
“The ideal number of arguments for a function is zero. Next comes one. Then two. Three arguments should be avoided where possible.”
Robert C Martin
- Flag arguments
Flag arguments, by design, signal that the function does more than one thing, which contradicts the single responsibility principle. If you see them, it means the function needs to be smaller.
- Argument objects
For functions that require three or more arguments, those arguments can be grouped together as an object and extracted into a class of their own. Now the argument group can have a name, improving readability.
- Argument lists
This is a special case where a function can take a variable number of arguments.
Comments
This is a subjective and heavily debated topic. While it is certainly ideal to express in code rather than in comments, there are times when plain English is simply more effective.
The express purpose of code is to communicate the “how”. It explains in intrinsic detail how something is done. It is the ultimate requirement specification that’s so detailed that a computer can execute it. If the code is clean enough, it should be able to express the how clearly without comments.
However, comments are particularly useful in expressing the “why”, i.e. the intent of a piece of code. Code can’t tell us why a calculation is done the way it is. Being able to understand the rationale behind the code provides a better context.
The Clean Code book highlights a number of examples of bad or unnecessary comments.
Code Smells
Programming is a highly creative and subjective process. Just as we can’t enable a computer to evaluate prose or quantify why Shakespeare’s writing is so highly revered, code can’t be measured in any objective way either.
Instead, we have to resort to “code smells”, which are general rules to evaluate the possibility of the code breaking. Martin Fowler describes it as
“a surface indication that’s quick to spot that corresponds to a deeper problem in the system”.
Examples of code smells include:
Bloaters: Code, methods, and classes that have grown to such humongous proportions that they’re hard to work with. Bloaters usually accumulate over time as a program evolves.
Object-Orientation Abusers: Incomplete or incorrect application of object-oriented programming principles.
Change Preventers: Code composition that requires change in multiple places in addition to the actual code the change is intended for.
Dispensables: Something pointless and unneeded, without which the code would be cleaner, more efficient, and easier to understand.
Robert C Martin identifies 67 different smells in Clean Code while Martin Fowler’s Refactoring specifies 23 smells.
Boundaries

When we’re designing a system, we might need to work with external software such as third-party libraries or APIs. This means having to integrate foreign code with our own—these points of integration form the boundary between internal and external code.
It’s important to keep the boundaries clean to prevent too much dependency between our code and external code. Better to depend on something you can control instead of something you can’t change.
A boundary is defined by an interface. The creator of the interface wants it to appeal to as broad an audience as possible, so it is usually quite large. A good example is ArrayList from .NET.
We can encapsulate internal and external boundaries to ensure that software failures don’t propagate throughout the system. We do this with learning tests, which are unit tests we build while learning the API.
Not only do learning tests document our learnings in code, but they are also useful for verification every time the API has a new release. This alerts interfacing components of errors and contains failures within those components.
Emergent Design
This is an approach that’s based on Agile principles where the software development process is seen as a learning process and design decisions are made as late as possible. Instead of pre-defining the design specifications upfront, the design emerges as the result of a permanent refactoring.
As the design emerges little by little, the code is built in small increments, typically using TDD with short red-green-refactor cycles. This results in a simpler design with a smaller codebase that’s easier to understand and maintain with less room for defects.
Kent Beck’s four rules of simple design, by order of priority (highest to lowest):
- Passes the tests
The most important rule of the four, “passes the tests” require tests to be in place first and foremost, to verify that the code works. Testable systems allow for software design that’s small with single-purpose classes.
With tests in place, we have the confidence and capacity to focus on refactoring to achieve quality code, which is what the following three rules provide for.
- Reveals intention
This rule underscores the significance of code that’s easy to understand. Code that clearly expresses its intention is key to ensuring that readers will understand its purpose.
- No duplication
Also expressed as DRY (Don’t Repeat Yourself) and SPOT (Single Point of Truth), the exercise of eliminating duplication helps manage and reduce the code complexity.
- Fewest elements
“anything that doesn’t serve the three prior rules should be removed.”
This rule seeks to minimize the number of classes and methods.
Successive Refinement
To quote Robert C Martin,
“To write clean code, you must first write dirty code and then clean it.”
Successive refinement is closely related to emergent design as both share the approach of constantly refining the code to create a high-quality, flexible system. It is simply not possible to write quality code in the first attempt, regardless of how familiar you are with the requirements.

Instead, we start by building a small subset of the requirements and go into a feedback loop where we continually refine the features until we reach the final solution.
Have you ever tried to take on a gigantic pull request from a colleague?
Many and large changes are a recipe for disaster which lead to a system that breaks for the next couple of releases until it recovers from the “change”.
With TDD however, we are able to grow the changes incrementally over time instead of in big chunks. We are able to split refactoring from features in separate pull requests to keep them manageable.
It is not uncommon to add things to the code and remove them again as part of refactoring. The goal is to keep the tests running at all times so our safety net is in place.
It is not enough for code to work. Code that works is often badly broken. Successive refinement of the code will have an enduring effect on the productivity of a team.
Get actionable insights on how to improve your code directly in your Inbox. Sign up now!
Are You Ready to Level Up Your Code?
Clean code takes considerable effort and discipline to master. It might be a simple concept in theory but it’s definitely not easy to put into practice, especially when you’re under pressure to deliver.

But if you’re serious about levelling up your code, and by extension, your value as a professional software developer, then the best thing you can do is to start honing your clean code skills. It will change the way you look at code and allow you to experience a much better working environment.
If you have questions about Clean Code or you’re experiencing specific issues with a particular aspect of it, you’re welcome to schedule a free 30-minute consultation with me. I would be more than happy to share some guidance to get you on the right track.
Illustration by Freepik Storyset
Share

Related Posts
Legal Stuff