


Adding unit tests to a legacy codebase is quite different beast than adding it to new code. It provides some unique challenges.
With new code, we have the luxury to apply principles like test-driven development and make sure the code is designed for testing. In a legacy codebase, we are given the code we must approach it with much more care.
If you have programmed systems for some time you have seen how most systems degenerate into a mess over time. What starts out as a crystal clear idea in the minds of the developers rots over time.
What starts out as a small and perfect system will by next year be a mess of classes and variables.
- What is it that causes this rot over time?
- Why can’t we grow the code without it going sour?
It is the customers’ fault for changing requirements you might say!
Requirements always change, it is our job as programmers to make our design flexible enough to cope. We or our colleges created a mess, but how do we manage it from here?
Most of the challenges in legacy codebases can be grouped into a few categories. I have picked three of them here. But first a pice of advice.
Never start a project to add test coverage to a codebase. It must be added little by little, organically
Dependency hell
Code that is written without thinking about tests often include dependencies that are hard to break from a test.
If a method contains code that new up objects, we can’t test the code because we can’t inject another version of the object that we control. An example of this the code below where the class SomethingService is a dependency we can’t affect from our test case.
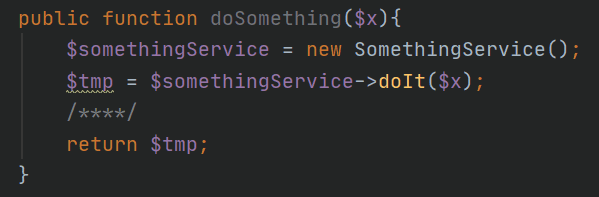
Eventhough we can’t test this code we can refactor it easily to be testable. We can introduce an overloaded version of the method that allows us to inject the dependency and make the existing code call the new method.
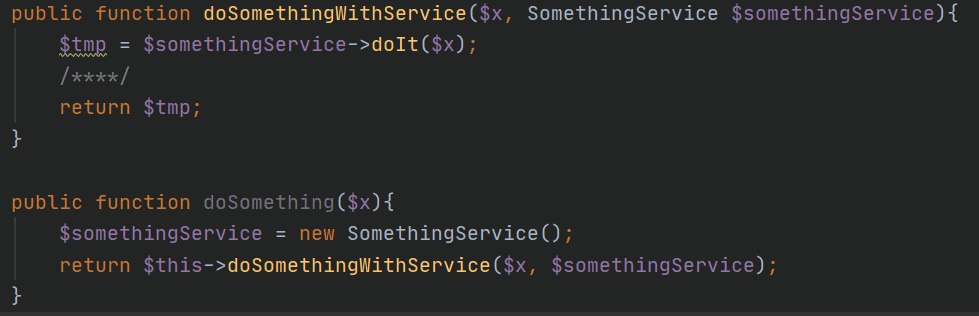
Using this method we have created a path to allow testing. We are still unable to test the original method, but since all logic is moved it is not a problem. It is important to notice that the current state is not the end goal but just a milestone. We should continue to refactor the code so we can remove the part of the code that new up dependencies. It could be to shift to dependency injection from the constructor of the class. But we need to start somewhere.
Breaking dependencies can be much more difficult than this example shows. One way to practice this skill is to use code katas
- https://github.com/codecop/dependency-breaking-katas (C# and Java)
- https://github.com/gregorriegler/dependency-breaker-kata (Java)
Create a safety net
The only safety net we have as programmers are tests. Any code that is not covered by tests we need to be extra careful when changing. We can easily introduce errors that will not surface until a customer complains that the software is broken.
So to protect ourselves from ourselves we need to make sure there is a safety net in place. We should always create a test harness around the code we need to change, before doing any changes to it. As soon as we have our safety net in place we can use it when refactoring the code.
Creating a test harness is much easier to explain using an example. The video below shows how to wrap an existing codebase in unit tests prepping it for refactoring.
Split refactoring and features
Have you ever had to review a pull request with thousands of changes all across the codebase?
Huge pull requests sucks. Intermingled and huge pull requests suck even more!
When looking at existing code it it often itching to cleanup the mess while we are there anyway. But this makes it very difficult for a reviewer to see which changes are related to the feature and which is part of the cleanup. Instead we must resist this itching and create one pull request for the feature changes and another for the cleanup. That approach has many benefits
- Each pull request has a clear purpose
- The changes are smaller
- It is easier to review a change that is small and with a clear intent
Make your colleges happy. Be disciplined and split refactorings and changes into different pull requests
Tags
Share

Legal Stuff